Data-centric AI
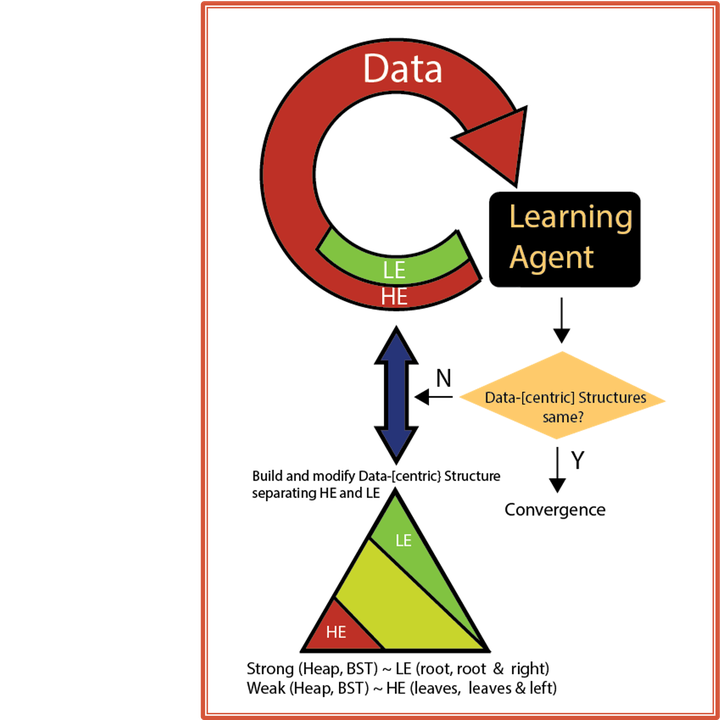
To deal with the unimaginable continual growth of data and the focus on its use rather than its governance, the value of data has begun to deteriorate seen in lack of reproducibility, validity, provenance, etc. In this work, we aim to simply understand what is the value of data and how this basic understanding might affect existing AI algorithms, in particular, EM-T (traditional expectation maximization) used in soft clustering and EM (a data-centric extension of EM-T). We have discovered that the value of data–or its “expressiveness" as we call it–is procedurally determined and runs the gamut from low expressiveness (LE) to high expressiveness (HE), the former not affecting the objective function much, while the latter a great deal. By using balanced binary search trees (BST) (complete orders) introduced here, we have improved on our earlier work that utilized heaps (partial orders) to separate LE from HE data. EM-DC (expectation maximization-data centric) significantly improve the performance of EM-T on big data. EM-DC is an improvement over EM by allowing more efficient identification of LE/HE data and its placement in the BST. Outcomes of this, aside from significant reduction in run-time over EM , while maintaining EM-T accuracy, include being able to isolate noisy data, convergence on data structures (using Hamming distance) rather than real-values, and the ability for the user to dictate the relative mixture of LE/HE acceptable for the run. The Python code and links to the data sets are provided in the paper. We additionally have released an R version (https://cran.r-project.org/web/packages/DCEM/index.html) that includes EM-T, EM , and k++ initialization.