Clustering Big Data
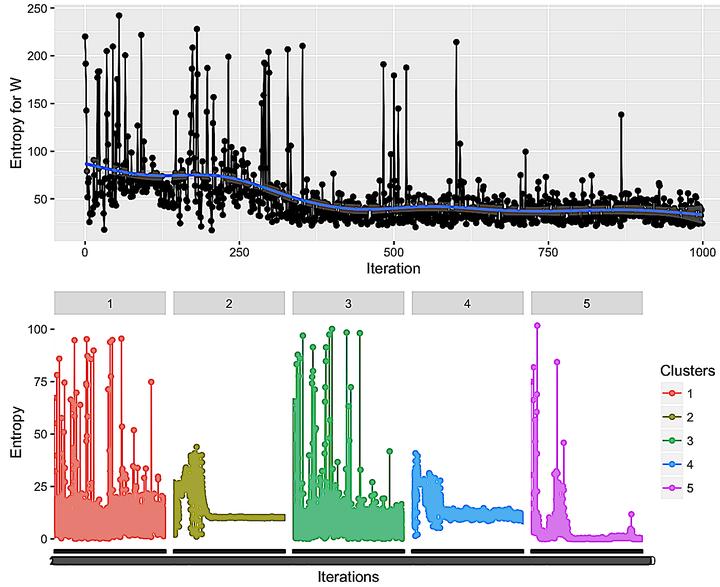
Existing data mining techniques, more particularly iterative learning algorithms, become overwhelmed with big data. While parallelism is an obvious and, usually, necessary strategy, we observe that both (1) continually revisiting data and (2) visiting all data are two of the most prominent problems especially for iterative, unsupervised algorithms like Expectation Maximization algorithm for clustering (EM-T). Our strategy is to embed EM-T into a non-linear hierarchical data structure (heap) that allows us to (1) separate data that needs to be revisited from data that does not and (2) narrow the iteration toward the data that is more difficult to cluster. We call this extended EM-T, EM*. We show our EM* algorithm outperform EM-T algorithm over large real world and synthetic data sets. We lastly conclude with some theoretic underpinnings that explain why EM* is successful.